
در دنیای امروز، اطلاعات فقط محدود به متن نیست؛ ما با تصویر، ویدیو، صدا و حتی دادههای حسی سر و کار داریم. مدلهای سنتی زبانی (مثل GPTهای فقط متنی) نمیتوانند به طور همزمان با چند نوع داده کار کنند.
اینجاست که مدلهای چندمودالی (Multimodal Language Models) وارد میدان میشوند. این مدلها قادرند متن، تصویر، ویدیو و حتی صدا را تحلیل و تولید کنند.
مزیتشون اینه که میتوانند فهم و پاسخدهی ما به دنیای پیچیده واقعی را شبیهسازی کنند.
مثال ملموس:
فرض کنید یک مدل چندمودالی دارید که میتواند یک عکس از خیابان را تحلیل کند و شما ازش بپرسید:
«چه چیزهایی در این عکس است؟»
مدل میتواند نه تنها اشیا را شناسایی کند، بلکه توضیح دهد که چه اتفاقی در صحنه در حال رخ دادن است، و حتی توضیح بده چه احساسی ممکن است تصویر منتقل کند.
| مزیتهای مدلهای چندمودالی | توضیح |
| توانایی پردازش همزمان چند نوع داده | متن، تصویر، ویدیو و صدا |
| تولید خروجیهای غنی و دقیق | پاسخهای بهتر نسبت به مدلهای تکمودالی |
| شبیهسازی نزدیکتر به توانایی انسانی | انسانها همواره چندمودالی فکر میکنند |
مودالیته، مدل زبانی بزرگ، چندمودالی بودن چیست؟
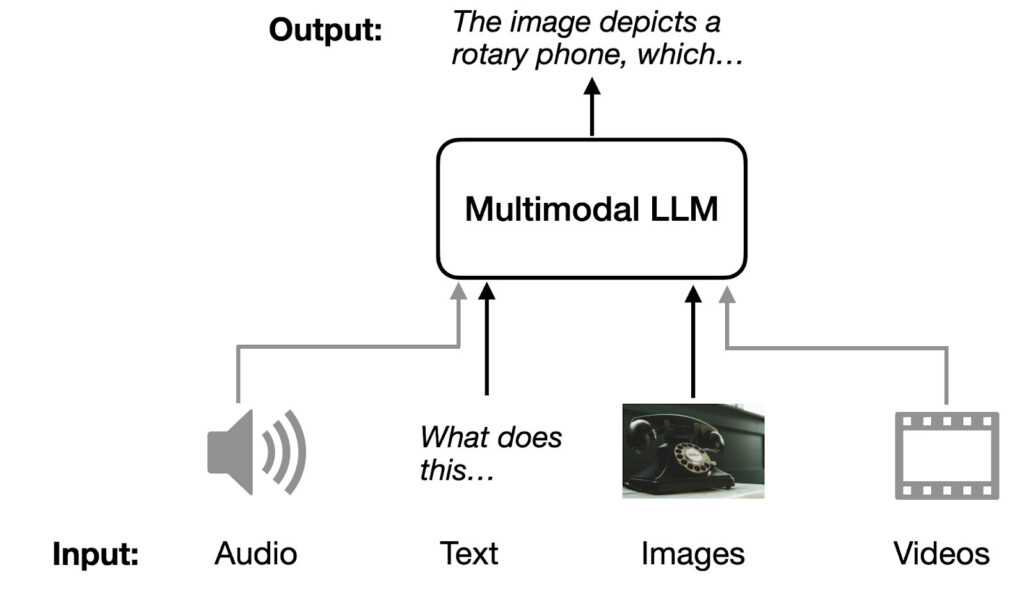
قبل از اینکه عمیقتر بریم، بهتره چند اصطلاح پایه را مشخص کنیم:
- مودالیته (Modality)
هر نوع داده یا کانال اطلاعاتی را یک مودالیته مینامیم؛ مثل متن، تصویر، ویدیو، صدا یا حتی دادههای حسگر. - مدل زبانی بزرگ (Large Language Model – LLM)
این مدلها شبکههای عصبی عظیمی هستند که میتوانند متن را بفهمند و تولید کنند. GPT-4 و PaLM نمونههای مشهور LLM هستند. - چندمودالی بودن (Multimodality)
وقتی یک مدل بتواند چند مودالیته را همزمان پردازش کند، میگوییم چندمودالی است.- مثال: یک مدل که هم متن و هم تصویر را تحلیل میکند.
- نمونه معروف: GPT-4o که میتواند متن و تصویر را پردازش کند.
| مفهوم | تعریف | مثال |
| مودالیته | نوع داده یا کانال اطلاعات | متن، تصویر، صدا |
| LLM | مدل زبانی بزرگ برای پردازش و تولید متن | GPT-4، PaLM |
| Multimodal | قابلیت پردازش همزمان چند مودالیته | GPT-4o، PaLM-E |
چطور مدلهای چندمودالی کار میکنند؟
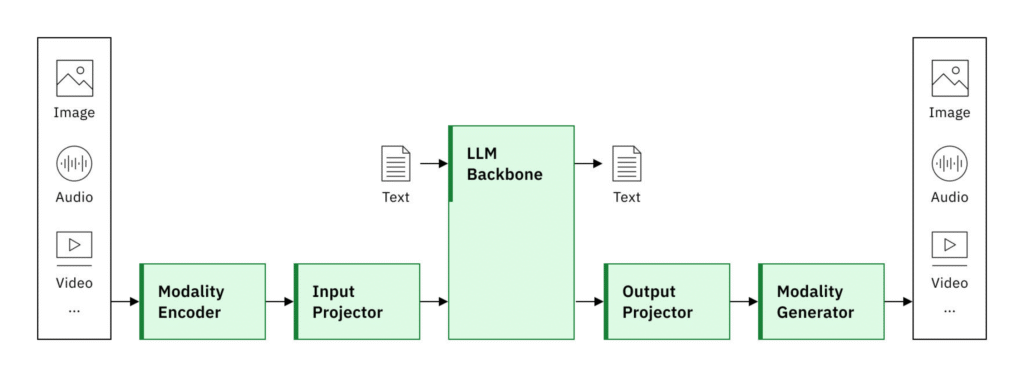
مدلهای چندمودالی ترکیبی از چند بخش اصلی هستند که با هم کار میکنند تا دادههای مختلف را تحلیل و تولید کنند:
- انکودر برای هر مودالیته
هر نوع داده (متن، تصویر، ویدیو، صدا) توسط یک انکودر مخصوص پردازش میشود.- مثال: تصویر وارد Vision Encoder میشود و ویژگیهای بصری آن استخراج میشود.
- متن وارد Text Encoder میشود و مفاهیم و معنا استخراج میشود.
- همترازی ویژگیها (Feature Alignment)
ویژگیهای استخراج شده از مودالیتههای مختلف باید در یک فضای مشترک قرار بگیرند تا مدل بتواند آنها را با هم مقایسه و ترکیب کند. - ادغام (Fusion)
ویژگیها بعد از همترازی با هم ترکیب میشوند و به یک بخش تولید خروجی (Decoder) فرستاده میشوند.- این بخش میتواند پاسخ متنی بدهد، تصویر تولید کند یا حتی چند مدیوم را همزمان تولید کند.
- تولید خروجی
مدل بر اساس دادههای ورودی، خروجی مناسب تولید میکند، که میتواند متن، تصویر یا هر ترکیبی باشد.
| بخش | وظیفه | مثال |
| انکودر | استخراج ویژگیهای هر مودالیته | Vision Encoder برای تصویر |
| همترازی ویژگیها | قرار دادن همه ویژگیها در یک فضای مشترک | متن و تصویر در یک embedding space |
| ادغام | ترکیب ویژگیها برای تولید خروجی | Multimodal Fusion |
محدودیتها و چالشها
با اینکه مدلهای چندمودالی (MLLMs) فوقالعادهاند، هنوز چالشهای مهمی وجود دارند که باید در نظر گرفت. بررسی این چالشها از معماری مدل تا مدیریت داده و منابع محاسباتی را شامل میشود:
1️⃣ معماری مدل و آموزش
- طراحی معماریای که بتواند به طور همزمان چند مودالیته را پردازش و تولید کند، کار پیچیدهای است.
- باید بین ظرفیت مدل، عملکرد و منابع مورد نیاز تعادل برقرار شود.
- آموزش مدل روی دادههای چندمودالی متنوع نیازمند GPUهای قوی، فضای ذخیرهسازی بزرگ و زمان طولانی است، بنابراین فرآیند هزینهبر است.
2️⃣ نمایش داده (Data Representation)
- یکی از چالشهای اصلی، نمایش یکپارچه دادهها از مودالیتههای مختلف است.
- هر مودالیته ویژگیها، فرمتها و ساختارهای خاص خود را دارد.
- ترکیب این دادهها به گونهای که هم غنای اطلاعات هر مودالیته حفظ شود و هم قابلیت تعامل بین مودالیتهها فراهم شود، پیچیده است.
3️⃣ جمعآوری و آمادهسازی دادهها
- جمعآوری و آمادهسازی دیتاستهای بزرگ، متنوع و با کیفیت بالا نیازمند منابع فراوان است.
- چالشهای حریم خصوصی و اخلاقی نیز مطرح است.
- نبود دیتاستهای جامع و برچسبخورده مناسب، آموزش مدلهای قدرتمند را محدود میکند.
4️⃣ ادغام مودالیتهها (Fusion)
- ادغام مودالیتهها یعنی ترکیب اطلاعات مختلف برای تولید یک خروجی منسجم.
- چالش این است که این ادغام باید اطلاعات هر مودالیته را حفظ کند و خروجی قابل فهم باشد.
- مکانیسمهایی مثل Cross-Attention برای گرفتن تعامل بین مودالیتهها استفاده میشوند.
5️⃣ دقت واقعی و سوگیری (Bias)
- مدلها ممکن است هالوسینیشن کنند (اطلاعات اشتباه اما جذاب تولید کنند).
- همچنین میتوانند سوگیریهای موجود در دادههای آموزش را به ارث ببرند و تقویت کنند.
6️⃣ حریم خصوصی
- پردازش دادههای حساس مانند تصویر، صدا و ویدیو ممکن است اطلاعات خصوصی را آشکار کند.
| چالش | توضیح |
| معماری و آموزش | طراحی مدل چندمودالی، تعادل بین ظرفیت، عملکرد و منابع |
| داده زیاد و متنوع | نیازمند دیتاستهای چندمودالی بزرگ و متنوع |
| نمایش دادهها | همترازی و یکپارچهسازی دادههای مختلف |
| ادغام مودالیتهها | ترکیب دادهها بدون از دست رفتن اطلاعات هر مودالیته |
| هالوسینیشن و سوگیری | تولید اطلاعات اشتباه یا تکرار سوگیریهای داده |
| محاسبات سنگین | نیاز به GPUهای قوی و زمان آموزش طولانی |
| حریم خصوصی | پردازش دادههای حساس ممکن است خطرناک باشد |
💡 نکته عملی: اگر دادهها به درستی آماده و مودالیتهها به خوبی همتراز نشوند، خروجی مدل میتواند مبهم یا نادرست باشد؛ حتی مدلهای پیشرفته مانند GPT‑4o یا PaLM‑E هم از این چالشها مصون نیستند.
کجا کاربرد دارد؟
مدلهای چندمودالی کاربردهای گسترده و هیجانانگیزی دارند، از جمله:
| حوزه کاربرد | مثال |
| بینایی کامپیوتر + متن | توضیح تصاویر، تولید کپشن برای عکسها |
| رباتیک و تعامل فیزیکی | رباتهایی که دستورهای متنی را روی محیط واقعی اجرا میکنند (مثل PaLM-E) |
| تحلیل ویدیو و صوت | شناسایی اشیا در ویدیو و تولید گزارش متنی از محتوا |
| تولید محتوا | ترکیب تصویر و متن برای ساخت تبلیغ یا محتوای هنری |
| پزشکی و تحلیل دادههای چندمودالی | تشخیص بیماری با تحلیل تصاویر پزشکی و گزارشهای متنی |
نکته: هر جا دادهها چندمودالی هستند، این مدلها میتوانند نسبت به مدلهای تکمودالی عملکرد بسیار بهتری ارائه دهند.
چه مدلهایی وجود دارند؟
در دنیای مدلهای چندمودالی، چند مدل برجسته و شناختهشده وجود دارند که هر کدام تمرکز و قابلیت خاص خود را دارند:
| مدل | نوع مودالیتهها | کاربرد اصلی | نکته کلیدی |
| GPT-4o | متن + تصویر | پاسخدهی به سوالات همراه با تحلیل تصویر | یکی از پیشرفتهترین مدلهای چندمودالی عمومی |
| PaLM‑E | متن + تصویر + محیط فیزیکی | رباتیک و تعامل با دنیای واقعی | میتواند دستورهای متنی را روی محیط فیزیکی اجرا کند |
| CoDi‑2 | متن + تصویر + صوت + ویدیو | تولید هر نوع مدیوم از مدیوم دیگر | توانایی تولید و تبدیل دادههای چندمودالی |
| LLaDA‑V | متن + تصویر | پردازش و تحلیل تصویر همراه متن | مناسب برای تعامل بصری و پرسش و پاسخ |
| MiniGPT‑4 | متن + تصویر | توضیح تصاویر و تولید کپشن | نسخه سبکتر GPT-4o برای کاربردهای عملی |
نکته: بسیاری از مدلهای جدید به سمت ادغام مودالیتههای بیشتر حرکت میکنند، تا تجربه انسانیتری از پردازش دادهها ایجاد کنند.
به کجا میرود؟
آینده مدلهای چندمودالی بسیار هیجانانگیز است. روندها نشان میدهند که:
- ادغام مودالیتههای بیشتر
- در آینده مدلها تنها متن و تصویر نیستند؛ بلکه صدا، حسگر، و حتی دادههای فیزیولوژیکی انسان را نیز ترکیب خواهند کرد.
- تولید دادههای چندمدیومی پیچیده
- مدلها قادر خواهند بود ویدیوها، صحنههای تعاملی و محیطهای شبیهسازیشده بسازند.
- کاربردهای واقعی و هوشمندتر
- رباتیک پیشرفته، آموزش تعاملی، هنر دیجیتال، تحلیل پزشکی و محیطهای تعاملی واقعیت مجازی.
- بهینهسازی و کوچکسازی مدلها
- با روشهایی مانند LoRA و QLoRA، مدلها سبکتر و قابل استفاده در محیطهای با منابع محدود خواهند شد.
نکته مهم: مسیر آینده مدلهای چندمودالی به سمت شبیهسازی نزدیکتر به هوش انسانی و همکاری با انسانها در محیط واقعی است.
جمعبندی و نگاه آینده
مدلهای چندمودالی (MLLMs) نشان میدهند که هوش مصنوعی میتواند فراتر از متن عمل کند و چندین نوع داده را همزمان تحلیل و تولید کند. این مدلها:
- توانایی درک و تولید محتوا در چندین مودالیته را دارند.
- تجربه نزدیکتری به توانایی انسانی در فهم دنیا ایجاد میکنند.
- در حوزههای متنوعی مثل بینایی کامپیوتر، رباتیک، تحلیل ویدیو و محتواهای خلاقانه کاربرد دارند.
با این حال، چالشها و محدودیتها مثل هالوسینیشن، نیاز به داده و محاسبات زیاد و مسائل حریم خصوصی هنوز وجود دارند.