
مدلهای زبانی بزرگ (Large Language Models یا LLMs) در سالهای اخیر پیشرفت چشمگیری داشتهاند و به ابزارهایی قدرتمند برای تولید متن، پاسخ به پرسشها و تعامل زبانی تبدیل شدهاند. با این حال، آموزش اولیه این مدلها بهتنهایی برای رسیدن به رفتارهای مطلوب، ایمن و همراستا با نیازهای انسانی کافی نیست.
اینجاست که یادگیری تقویتی (Reinforcement Learning یا RL) نقش کلیدی پیدا میکند.
در این بلاگ پست، بهصورت کلی اما علمی بررسی میکنیم که RL چیست، چرا در مدلهای زبانی اهمیت دارد و چگونه به بهبود کیفیت و همسویی خروجی LLMها کمک میکند.
یادگیری تقویتی (Reinforcement Learning) به زبان ساده
یادگیری تقویتی (Reinforcement Learning یا RL) یکی از پارادایمهای اصلی یادگیری ماشین است که تمرکز آن بر تصمیمگیری متوالی در یک محیط پویا است.
در RL، یک عامل (Agent) با انجام عملهایی در محیط و دریافت بازخورد عددی (پاداش یا جریمه)، بهمرور یاد میگیرد که چگونه رفتار خود را بهینه کند.
برخلاف یادگیری نظارتشده که پاسخ درست از قبل مشخص است، در یادگیری تقویتی عامل باید با آزمونوخطا یاد بگیرد چه تصمیمهایی در بلندمدت بهترین نتیجه را میدهند.
اجزای اصلی یادگیری تقویتی
هر سیستم RL از چند مؤلفهی کلیدی تشکیل شده است:
| مؤلفه | توضیح |
|---|---|
| Agent (عامل) | موجودیتی که تصمیم میگیرد و عمل انجام میدهد |
| Environment (محیط) | سیستمی که عامل با آن تعامل دارد |
| Action (عمل) | تصمیم یا اقدامی که عامل انجام میدهد |
| Reward (پاداش) | بازخورد عددی برای ارزیابی کیفیت عمل |
| Policy (سیاست) | استراتژی عامل برای انتخاب عملها |
هدف عامل این است که سیاستی (Policy) یاد بگیرد که پاداش تجمعی را در طول زمان بیشینه کند.
RL در مدلهای زبانی چگونه تعریف میشود؟
وقتی یادگیری تقویتی را به دنیای مدلهای زبانی بزرگ (LLMs) میآوریم، این مفاهیم به شکل زیر تفسیر میشوند:
| مفهوم در RL | معادل در مدل زبانی |
|---|---|
| Agent | مدل زبانی |
| Environment | مکالمه، کاربر یا کانتکست ورودی |
| Action | تولید یک توکن یا یک پاسخ کامل |
| Reward | امتیاز کیفیت، مفید بودن یا مطلوب بودن پاسخ |
| Policy | احتمال تولید توکنها توسط مدل |
به این ترتیب، تولید متن دیگر فقط یک فرآیند آماری نیست، بلکه به یک مسئله تصمیمگیری تبدیل میشود.
مثال ساده: تفاوت آموزش معمولی و RL
فرض کنید از یک مدل زبانی این سؤال را میپرسیم:
«چطور میتوانم تمرکز خودم را هنگام مطالعه افزایش بدهم؟»
🔹 آموزش معمولی (Pretraining)
مدل پاسخی میدهد که از نظر آماری شبیه پاسخهای دیدهشده در دادههای آموزشی است، اما:
- ممکن است خیلی کلی باشد
- یا بیش از حد طولانی
- یا حتی توصیههای غیرعملی بدهد
🔹 با یادگیری تقویتی
مدل براساس پاداش یاد میگیرد که:
- پاسخ مختصر اما کاربردی بدهد
- لحن مناسب داشته باشد
- توصیههای واقعبینانه ارائه کند
در این حالت، مدل فقط نمیپرسد «کدام پاسخ محتملتر است؟»
بلکه میپرسد:
«کدام پاسخ بهتر است؟»
تفاوت کلیدی RL با سایر روشهای یادگیری
| روش یادگیری | معیار بهینهسازی |
|---|---|
| یادگیری نظارتشده | شباهت به برچسبهای داده |
| یادگیری خودنظارتی | پیشبینی دقیق توکن بعدی |
| یادگیری تقویتی | بیشینهسازی پاداش رفتاری |
این تفاوت باعث میشود RL ابزار مناسبی برای کنترل رفتار مدلهای زبانی باشد، نه فقط افزایش دقت آماری آنها.
چرا RL برای LLMها حیاتی است؟
یادگیری تقویتی به مدلهای زبانی اجازه میدهد:
- کیفیت پاسخ را از دید انسان درک کنند
- رفتار خود را در طول مکالمه اصلاح کنند
- و به اهدافی فراتر از «درستبودن زبانی» برسند
به همین دلیل، RL پایهی بسیاری از تکنیکهای پیشرفته مانند RLHF است که در مدلهای زبانی مدرن استفاده میشود.

یادگیری تقویتی با بازخورد انسانی (RLHF) چیست و چرا مهم است؟
یکی از مهمترین و پرکاربردترین شکلهای یادگیری تقویتی در مدلهای زبانی بزرگ، یادگیری تقویتی با بازخورد انسانی یا Reinforcement Learning from Human Feedback (RLHF) است.
RLHF پاسخی مستقیم به یک چالش اساسی در LLMهاست:
چگونه میتوان مدلی ساخت که نهتنها از نظر زبانی درست، بلکه از نظر انسانی «مطلوب» باشد؟
مسئلهای که RLHF حل میکند
مدلهای زبانی در مرحله پیشآموزش (Pretraining):
- فقط بر اساس احتمال آماری توکنها آموزش میبینند
- درک مستقیمی از مفاهیمی مثل مفید بودن، ایمن بودن یا مؤدب بودن ندارند
- ممکن است پاسخهایی تولید کنند که از نظر زبانی صحیح، اما از نظر انسانی نامناسب باشند
RLHF این شکاف را با وارد کردن قضاوت انسانی به فرآیند آموزش پر میکند.
فرآیند RLHF بهصورت مرحلهبهمرحله
RLHF معمولاً در سه مرحلهی اصلی انجام میشود:
1️⃣ آموزش مدل پایه (Pretrained Model)
مدل زبانی ابتدا با روشهای رایج (مثل پیشبینی توکن بعدی) روی دادههای متنی بزرگ آموزش داده میشود.
در این مرحله، مدل زبان را خوب یاد میگیرد اما هنوز همراستایی انسانی ندارد.
2️⃣ جمعآوری ترجیحات انسانی و آموزش مدل پاداش
در این مرحله:
- مدل چند پاسخ مختلف به یک پرسش تولید میکند
- انسانها این پاسخها را مقایسه یا رتبهبندی میکنند
- دادههای حاصل برای آموزش یک مدل پاداش (Reward Model) استفاده میشود
مدل پاداش یاد میگیرد که:
کدام پاسخ از نظر انسان بهتر است و چرا
3️⃣ بهینهسازی مدل با یادگیری تقویتی
در نهایت:
- مدل زبانی بهعنوان Agent در نظر گرفته میشود
- مدل پاداش نقش محیط و منبع پاداش را دارد
- با الگوریتمهایی مثل PPO (Proximal Policy Optimization)، مدل طوری بهروزرسانی میشود که پاداش بیشتری بگیرد
نتیجه این فرآیند، مدلی است که خروجیهایش با ترجیحات انسانی همسوتر است.
اجزای RLHF در یک نگاه
| مؤلفه | نقش در RLHF |
|---|---|
| مدل زبانی | عامل (Agent) |
| انسان | منبع قضاوت و ترجیح |
| مدل پاداش | تقریب قضاوت انسانی |
| الگوریتم RL | بهینهسازی رفتار مدل |
| پاداش | میزان مطلوب بودن پاسخ |
این معماری باعث میشود RLHF هم مقیاسپذیر باشد و هم از قضاوت انسانی بهره ببرد.
مثال واقعی: چرا RLHF کیفیت پاسخ را بهتر میکند؟
فرض کنید پرسش زیر مطرح شود:
«یک توصیه پزشکی ساده بده.»
🔹 بدون RLHF
مدل ممکن است:
- توصیهای کلی، مبهم یا حتی نادرست بدهد
- هشدارهای ایمنی را نادیده بگیرد
- لحن نامناسب داشته باشد
🔹 با RLHF
مدل یاد میگیرد که:
- از توصیههای خطرناک پرهیز کند
- محدودیتهای دانش خود را بیان کند
- کاربر را به منابع معتبر یا پزشک ارجاع دهد
این تفاوت، نتیجهی پاداشدهی به رفتارهای ایمن و مسئولانه است.
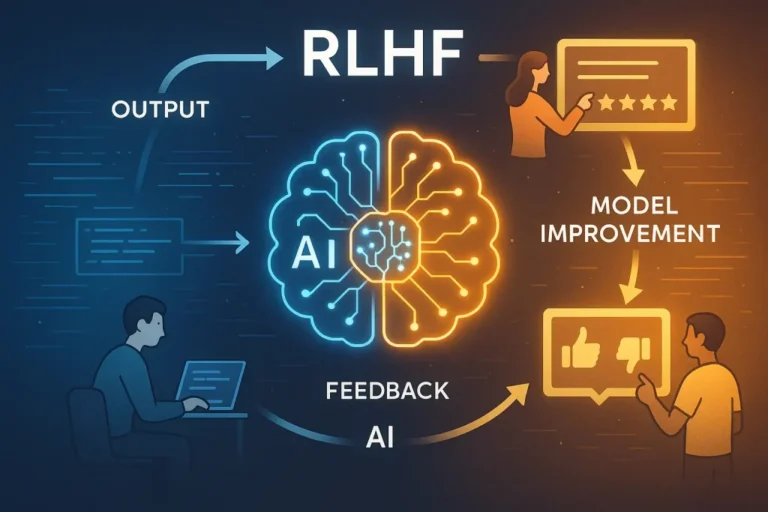
چرا RLHF برای مدلهای زبانی حیاتی است؟
RLHF به مدلهای زبانی کمک میکند تا:
- از دید انسان «پاسخ خوب» را یاد بگیرند
- رفتار خود را با کاربردهای واقعی سازگار کنند
- اعتمادپذیرتر و قابل استفادهتر شوند
به همین دلیل، بسیاری از مدلهای زبانی مدرن در محصولات واقعی، از RLHF بهعنوان مرحلهی کلیدی آموزش استفاده میکنند.
روشهای مرتبط با RLHF: از RLAIF تا DPO
اگرچه RLHF یکی از رایجترین روشهای همسوسازی مدلهای زبانی است، اما محدودیتهایی مانند هزینه و مقیاسپذیری باعث شده روشهای جایگزین و مکملی توسعه پیدا کنند.
🔁 RLAIF: یادگیری تقویتی با بازخورد هوش مصنوعی
در Reinforcement Learning from AI Feedback (RLAIF)، بهجای انسان:
- یک مدل زبانی دیگر نقش ارزیاب را بازی میکند
- پاسخها را مقایسه و امتیازدهی میکند
مزیت اصلی: کاهش هزینه و افزایش مقیاس
چالش: احتمال انتقال سوگیریهای مدل ارزیاب
⚡ DPO: بهینهسازی مستقیم ترجیحات
Direct Preference Optimization (DPO) رویکردی سادهتر است که:
- مرحله کلاسیک RL را حذف میکند
- مستقیماً از دادههای ترجیحی برای بهینهسازی مدل استفاده میکند
DPO در بسیاری از کاربردها:
- پایدارتر
- سادهتر
- و سریعتر از RLHF عمل میکند

📈 مزایا و چالشهای استفاده از RL در مدلهای زبانی
✅ مزایا
- همسویی بهتر با ترجیحات انسانی
- بهبود کیفیت پاسخ در کاربردهای واقعی
- افزایش ایمنی و کنترلپذیری مدل
⚠️ چالشها
- تعریف دقیق «پاداش خوب»
- حساسیت به دادههای ترجیحی
- خطر بیشبرازش به سلیقههای خاص
به همین دلیل، استفاده از RL نیازمند طراحی دقیق و ارزیابی مداوم است.
مثال کاربردی: RL در محصولات واقعی
در چتباتها و دستیارهای هوشمند:
- RL برای بهبود لحن، مفید بودن و ایمنی پاسخها استفاده میشود
- مدل یاد میگیرد چه زمانی پاسخ ندهد یا هشدار بدهد
- کیفیت تجربه کاربر بهمرور افزایش پیدا میکند
این نوع بهینهسازی بدون یادگیری تقویتی عملاً امکانپذیر نیست.

جمعبندی
یادگیری تقویتی، بهویژه در قالب RLHF و روشهای جدیدتر مانند DPO، نقش کلیدی در تبدیل مدلهای زبانی به سیستمهایی قابل اعتماد، همسو با انسان و کاربردی دارد.
در آینده، انتظار میرود:
- اتکا به بازخورد انسانی کمتر شود
- روشهای سادهتر و مقیاسپذیرتر رواج پیدا کنند
- RL به بخشی جدانشدنی از آموزش LLMها تبدیل شود
در نهایت، RL پلی است بین «مدلی که زبان را بلد است» و «مدلی که رفتار درست دارد».