
احتمالاً برای شما هم پیش آمده که در حال گفتگو با یک مدل زبانی مثل ChatGPT باشید، چند پیام جلوتر بروید و ناگهان حس کنید مدل چیزی را که چند دقیقه قبل گفته بودید فراموش کرده است.
مثلاً دوباره سؤالی میپرسد که پاسخ آن قبلاً داده شده، یا پاسخی میدهد که انگار هیچ ارتباطی با بحث قبلی ندارد. در چنین لحظهای معمولاً این سؤال به ذهن میرسد:
«مگر این مدل حافظه ندارد؟»
از طرف دیگر، گاهی دقیقاً برعکس این اتفاق میافتد. مدل میتواند بهخوبی به اطلاعاتی که چند پیام قبل مطرح شده ارجاع بدهد، پاسخها را در همان چارچوب ادامه دهد و حتی جزئیاتی را به خاطر بیاورد که برای ادامهی گفتگو مهم هستند. این رفتار دوگانه باعث میشود مفهوم حافظه در مدلهای زبانی به یکی از جذابترین و در عین حال مبهمترین موضوعات در هوش مصنوعی تبدیل شود.
در گفتگوهای انسانی، حافظه نقش اساسی دارد. ما حرفهای قبلی را به خاطر میسپاریم، زمینهی بحث را نگه میداریم و بر اساس تجربهی گذشته پاسخ میدهیم. مدلهای زبانی هم برای اینکه بتوانند مکالمهای منسجم، مرتبط و طبیعی داشته باشند، به نوعی از حافظه نیاز دارند. اما این حافظه دقیقاً چیست؟ آیا شبیه حافظهی انسان عمل میکند؟ و چرا با وجود پیشرفت چشمگیر مدلهای زبانی، هنوز هم با «فراموشی» روبهرو میشویم؟
برای پاسخ به این پرسشها، ابتدا باید بفهمیم وقتی از حافظه در مدلهای زبانی صحبت میکنیم، دقیقاً منظورمان چیست و این مفهوم چه تفاوتی با حافظهی انسانی دارد. اینجاست که بحث اصلی ما شروع میشود.
حافظه در مدلهای زبانی دقیقاً یعنی چه؟
وقتی کاربران از «حافظه» در مدلهای زبانی صحبت میکنند، معمولاً منظورشان چیز سادهای است:
اینکه مدل بتواند حرفهایی را که قبلاً گفتهایم به خاطر بسپارد و در ادامهی گفتگو از آنها استفاده کند. از این زاویه، حافظه یعنی یادآوری اسمها، ترجیحات، موضوع بحث و هر اطلاعاتی که باعث میشود پاسخها مرتبط و منسجم بمانند.
اما از نگاه فنی، مفهوم حافظه در مدلهای زبانی کمی متفاوت است و همین تفاوت، منشأ بسیاری از سوءتفاهمهاست.
حافظه با یادگیری یکی نیست
اولین نکتهی مهم این است که حافظه با یادگیری تفاوت دارد.
یادگیری در مدلهای زبانی در مرحلهی آموزش (training) اتفاق میافتد؛ جایی که مدل با دیدن حجم عظیمی از دادهها، الگوهای زبانی را یاد میگیرد و پارامترهایش تنظیم میشوند. این نوع یادگیری پایدار است و بعد از پایان آموزش تغییر نمیکند.
در مقابل، حافظه به توانایی مدل برای استفاده از اطلاعات موجود در بافت فعلی گفتگو اشاره دارد. یعنی مدل چیزی را «یاد نمیگیرد» که برای همیشه در ذهنش بماند، بلکه فقط از اطلاعاتی استفاده میکند که در لحظه در اختیار دارد.
به بیان ساده:
-
یادگیری ← تغییر بلندمدت در مدل
-
حافظه ← استفادهی موقت از اطلاعات قبلی
حافظه یعنی استفاده از اطلاعات قبلی در پاسخ فعلی
در مدلهای زبانی، حافظه معمولاً به این معناست که مدل بتواند:
-
پیامهای قبلی گفتگو را در نظر بگیرد
-
روابط بین آنها را بفهمد
-
و پاسخ فعلی را با در نظر گرفتن پیامها و اطلاعات قبلیِ موجود در گفتگو تولید کند.
مثلاً اگر در ابتدای گفتگو موضوع مشخصی مطرح شده باشد، مدل باید بتواند در ادامه به همان موضوع ارجاع دهد، بدون اینکه کاربر مجبور باشد همهچیز را دوباره توضیح دهد. این توانایی، همان چیزی است که از دید کاربر بهعنوان «حافظه داشتن مدل» تجربه میشود.
تفاوت نگاه کاربر و نگاه فنی به حافظه
از دید کاربر، حافظه اغلب شبیه حافظهی انسانی تصور میشود:
چیزی پایدار که مدل آن را نگه میدارد و بعداً هم به یاد میآورد. اما از دید فنی، بیشتر مدلهای زبانی حافظهی واقعی و ماندگار ندارند. آنچه وجود دارد، یک پنجرهی محدود از متن قبلی است که مدل هنگام تولید پاسخ به آن دسترسی دارد.
به همین دلیل است که مدل ممکن است در یک گفتگو عملکردی شبیه به داشتن حافظه داشته باشد، اما با پایان مکالمه یا خروج از محدودهی بافت، آن اطلاعات از دست بروند. این تفاوت دیدگاه کمک میکند بهتر بفهمیم چرا مدلهای زبانی گاهی بسیار «باهوش» و گاهی کاملاً «فراموشکار» به نظر میرسند.
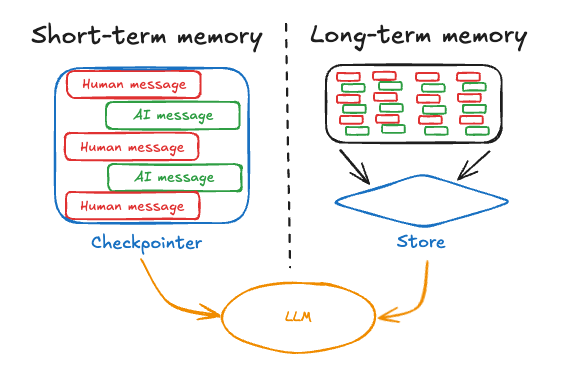
مدلهای زبانی چه چیزی را و کِی به خاطر میسپارند؟
یکی از رایجترین سوءتفاهمها دربارهی مدلهای زبانی این است که تصور میشود آنها مثل انسانها بهصورت فعال تصمیم میگیرند چه چیزی را به خاطر بسپارند و چه چیزی را فراموش کنند. در حالی که در عمل، حافظهی مدلهای زبانی بسیار محدودتر و مکانیکیتر از این تصور است.
حافظه فقط در طول یک مکالمه معنا دارد
در اغلب مدلهای زبانی، حافظه تنها در چارچوب یک مکالمهی مشخص وجود دارد. یعنی مدل میتواند پیامهای قبلی همان گفتگو را ببیند و بر اساس آنها پاسخ بدهد، اما با پایان مکالمه یا شروع یک گفتگوی جدید، این اطلاعات دیگر در دسترس نیستند.
به بیان ساده، مدل چیزی را «نگه نمیدارد» که بعداً دوباره به آن مراجعه کند؛ بلکه فقط از آنچه در همان لحظه جلوی چشمش قرار دارد استفاده میکند. به همین دلیل است که اگر اطلاعات مهمی را در ابتدای گفتگو بگویید اما گفتگو خیلی طولانی شود، مدل ممکن است در ادامه آن را نادیده بگیرد یا فراموش کند.
وابستگی حافظه به context
آنچه معمولاً بهعنوان حافظه در مدلهای زبانی شناخته میشود، در واقع همان context یا بافت متنی است. این بافت شامل مجموعهای از پیامهای قبلی است که مدل هنگام تولید پاسخ به آنها دسترسی دارد.
اگر اطلاعاتی داخل این بافت قرار داشته باشد، مدل میتواند از آن استفاده کند؛ اگر خارج از آن باشد، عملاً برای مدل وجود ندارد. بنابراین «به خاطر سپردن» در مدلهای زبانی نه به اهمیت اطلاعات، بلکه به جایگاه آن در بافت گفتگو وابسته است.
این موضوع توضیح میدهد چرا گاهی مدل جزئیات کماهمیتِ نزدیک را به یاد دارد، اما نکات مهمتری را که زودتر گفته شدهاند، از دست میدهد.
مدل خودش تصمیم نمیگیرد چه چیزی مهم است
برخلاف انسانها، مدلهای زبانی آگاهی یا قصد ندارند. آنها تصمیم نمیگیرند که «این نکته مهم است، پس نگهش دارم». همهچیز به نحوهی ارائهی اطلاعات و محدودیتهای بافت بستگی دارد.
مدل صرفاً تلاش میکند بر اساس توزیع احتمالات، بهترین پاسخ ممکن را با توجه به متنی که در اختیار دارد تولید کند. اگر اطلاعات کلیدی به شکلی واضح، تکرارشده یا نزدیک به سؤال نهایی مطرح شده باشند، احتمال استفاده از آنها بیشتر است. اما این به معنای فهم یا اولویتبندی آگاهانه نیست.
در نتیجه، وقتی میگوییم یک مدل زبانی چیزی را «به خاطر میسپارد»، در واقع منظورمان این است که آن اطلاعات هنوز در محدودهی بافت قابل پردازش مدل قرار دارند، نه اینکه مدل آنها را مانند یک حافظهی پایدار ذخیره کرده باشد.
چرا حافظه برای مدلهای زبانی ضروری است؟
اگر مدلهای زبانی هیچ دسترسیای به اطلاعات قبلی گفتگو نداشتند، هر پیام عملاً یک سؤال مستقل محسوب میشد. در چنین حالتی، مکالمهی پیوسته و معنادار تقریباً غیرممکن بود. حافظه (یا دقیقتر بگوییم، استفاده از context) نقش کلیدی در قابلاستفاده شدن مدلهای زبانی ایفا میکند.
حفظ انسجام در گفتگو
یکی از مهمترین نقشهای حافظه در مدلهای زبانی، حفظ انسجام مکالمه است. وقتی کاربر در چند پیام متوالی دربارهی یک موضوع صحبت میکند، انتظار دارد پاسخها به هم مرتبط باشند و مسیر گفتگو حفظ شود.
حافظه باعث میشود مدل:
-
بداند موضوع بحث چیست
-
به پیامهای قبلی ارجاع بدهد
-
و پاسخهایی تولید کند که ادامهی منطقی گفتگو باشند
بدون این قابلیت، هر پاسخ شبیه شروع یک مکالمهی جدید خواهد بود.
کاهش پاسخهای بیربط و سردرگمکننده
بسیاری از پاسخهای بیربط یا ناهماهنگ مدلها، نه بهدلیل ضعف زبانی، بلکه بهدلیل از دست رفتن بافت گفتگو اتفاق میافتند. وقتی مدل به اطلاعات قبلی دسترسی دارد، احتمال اینکه پاسخ خارج از موضوع بدهد یا فرضهای نادرست بسازد، بهطور قابلتوجهی کاهش پیدا میکند.
به همین دلیل است که حافظه نقش مستقیمی در:
-
افزایش دقت پاسخها
-
کاهش سوءبرداشت از سؤال کاربر
-
و بهبود تجربهی کلی تعامل
دارد.
امکان شخصیسازی تعامل
حافظه همچنین پایهی اصلی تعامل شخصیسازیشده با مدلهای زبانی است. اگر مدل بتواند اطلاعاتی مثل ترجیحات کاربر، سطح دانش، یا هدف گفتگو را در طول مکالمه در نظر بگیرد، پاسخها طبیعیتر و مفیدتر میشوند.
حتی در سادهترین حالت، به خاطر سپردن این که «کاربر قبلاً چه پرسیده» یا «در چه زمینهای صحبت میکنیم»، نوعی شخصیسازی حداقلی ایجاد میکند که برای کاربر بسیار ارزشمند است.
کاربرد در سیستمهای واقعی: چتبات، دستیار، Agent
در سیستمهای واقعی مبتنی بر مدلهای زبانی، مثل:
-
چتباتهای پشتیبانی
-
دستیارهای هوشمند
-
یا agentهای خودکار
حافظه یک قابلیت لوکس نیست، بلکه یک نیاز اساسی است. این سیستمها باید بتوانند:
-
وضعیت کاربر را دنبال کنند
-
مراحل قبلی را به خاطر داشته باشند
-
و تصمیمها را در بستر یک فرآیند چندمرحلهای بگیرند
بدون حافظه، چنین سیستمهایی عملاً به مجموعهای از پاسخهای جدا از هم تبدیل میشوند.
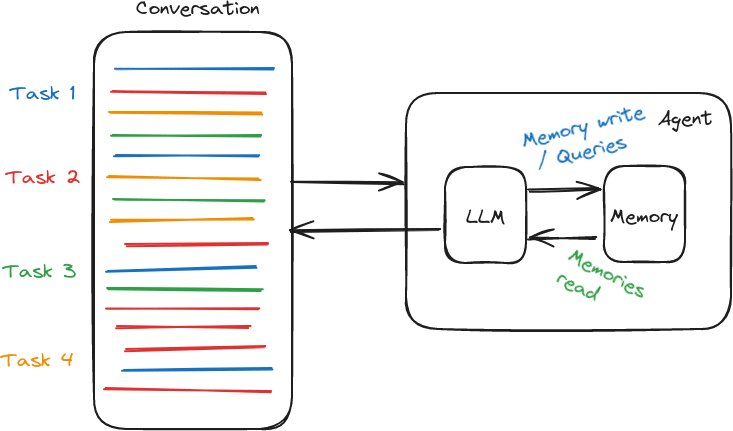
محدودیتهای حافظه در مدلهای زبانی
با وجود اهمیت بالای حافظه، مدلهای زبانی امروزی محدودیتهای جدی در این زمینه دارند. درک این محدودیتها کمک میکند انتظارات واقعبینانهتری از عملکرد آنها داشته باشیم.
محدودیت پنجرهی متن (Context Window)
مهمترین محدودیت حافظه در مدلهای زبانی، اندازهی محدود پنجرهی متن است. مدل فقط میتواند مقدار مشخصی از متن قبلی را ببیند. اگر مکالمه طولانیتر از این حد شود، بخشهای قدیمیتر از بافت حذف میشوند.
این یعنی:
-
اطلاعات قدیمی، حتی اگر مهم باشند، ممکن است از دست بروند
-
مدل الزاماً «فراموشکار» نیست، بلکه دیگر به آن اطلاعات دسترسی ندارد
فراموشی اطلاعات قدیمی در مکالمات طولانی
در مکالمات طولانی، معمولاً اطلاعات جدید جای اطلاعات قدیمی را میگیرند. به همین دلیل است که مدل ممکن است جزئیاتی را که در ابتدای گفتگو گفته شدهاند، در ادامه نادیده بگیرد.
این فراموشی:
-
انتخاب آگاهانه نیست
-
نشانهی ضعف فهم نیست
بلکه نتیجهی مستقیم محدودیتهای فنی حافظه است.
تفاوت حافظهی موقت و حافظهی پایدار
حافظهای که تاکنون دربارهاش صحبت کردیم، عمدتاً موقت است؛ یعنی فقط در طول یک مکالمه یا یک context وجود دارد. در مقابل، حافظهی پایدار چیزی است که بتواند اطلاعات را در طول زمان ذخیره کند و در تعاملات بعدی هم به آنها دسترسی داشته باشد.
بیشتر مدلهای زبانی بهصورت پیشفرض چنین حافظهی پایداری ندارند، و پیادهسازی آن معمولاً نیازمند سیستمهای جانبی و طراحیهای اضافی است. همین تفاوت، یکی از چالشهای اصلی توسعهی مدلهای زبانی پیشرفتهتر محسوب
میشود.
انواع حافظه در سیستمهای مبتنی بر مدلهای زبانی
در کاربردهای واقعی مدلهای زبانی، مفهوم حافظه معمولاً فقط به «متن قبلی گفتگو» محدود نمیشود. بسیاری از سیستمهای پیشرفتهتر، حافظه را به شکل ساختارمندتری طراحی میکنند؛ ساختاری که تا حدی از حافظهی انسان الهام گرفته شده است. در این نگاه، حافظه انواع مختلفی دارد که هر کدام نقش مشخصی در ساخت سیستمهای هوشمند و سازگار با زمینه ایفا میکنند.
بهطور کلی، میتوان حافظه در سیستمهای مبتنی بر LLM را به سه نوع اصلی تقسیم کرد: حافظه معنایی، حافظه رویدادی و حافظه رویهای.
1)حافظه معنایی (Semantic Memory): دانش و حقایق
حافظهی معنایی شامل دانش، حقایق و اطلاعات پایدار است؛ اطلاعاتی که مستقیماً محتوای پاسخهای مدل را شکل میدهند.
در یک سیستم مبتنی بر LLM، این نوع حافظه میتواند شامل مواردی مثل:
-
ترجیحات کاربر
-
اطلاعات پروفایل (نام، زبان، سبک پاسخ)
-
دانستههای ساختاریافته دربارهی موضوعات مختلف
دو روش رایج برای نمایش حافظهی معنایی وجود دارد: Collection و Profile.
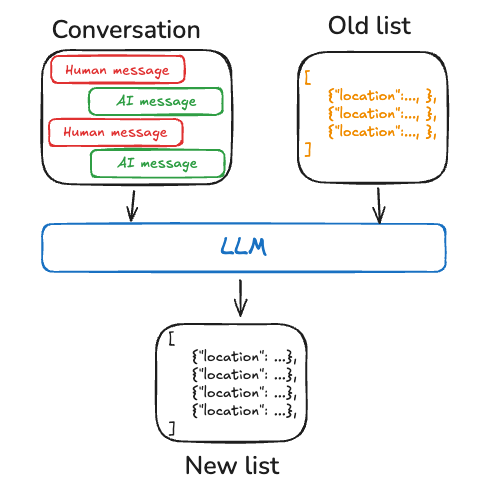
🔶Collection (مجموعه خاطرات)
در این روش، حافظه بهصورت مجموعهای از اسناد یا رکوردهای مستقل ذخیره میشود. هر تعامل جدید میتواند خاطرات جدیدی به این مجموعه اضافه کند. این رویکرد برای زمانی مناسب است که:
-
حجم اطلاعات زیاد است
-
لازم است خاطرات قدیمی حفظ شوند
-
بازیابی اطلاعات بهصورت زمینهمحور انجام شود
البته این روش چالشهایی هم دارد؛ سیستم باید تشخیص دهد کدام اطلاعات جدید واقعاً ارزش ذخیرهسازی دارند و چگونه اطلاعات قدیمی را بهروزرسانی یا ادغام کند. ذخیرهی بیش از حد میتواند دقت بازیابی را کاهش دهد و ذخیرهی کمحد هم باعث از دست رفتن اطلاعات مهم شود.
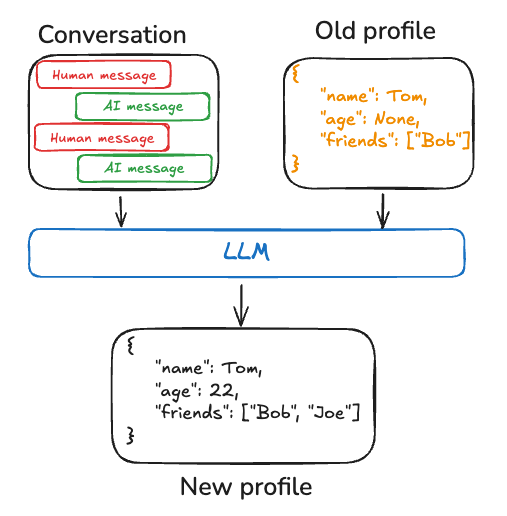
🔶Profile (پروفایل)
پروفایلها رویکردی ساختاریافتهتر دارند. در این حالت، حافظه بهصورت یک سند واحد نگهداری میشود که وضعیت فعلی کاربر یا عامل را نشان میدهد؛ مثل:
-
هدف اصلی کاربر
-
سبک مورد علاقه در پاسخگویی
-
اطلاعات هویتی یا تنظیمات مهم
برخلاف collection، وقتی اطلاعات جدید وارد میشود، پروفایل بهروزرسانی میشود نه اینکه یک خاطرهی جدید اضافه شود. این روش زمانی ایدهآل است که:
-
فقط «وضعیت فعلی» مهم است
-
نمیخواهیم اطلاعات زائد یا قدیمی نگه داریم
-
شخصیسازی سریع و شفاف اهمیت دارد
2)حافظه رویدادی (Episodic Memory): تجربههای گذشته
حافظهی رویدادی مربوط به تجربههای کامل و موفق گذشته است. این نوع حافظه فقط شامل «دانش» نیست، بلکه:
-
زمینهی تعامل
-
مسیر رسیدن به پاسخ
-
و دلیل موفقیت آن پاسخ
را نیز در خود نگه میدارد.
در سیستمهای LLM، حافظهی رویدادی معمولاً برای:
-
نگهداشتن مثالهای موفق (few-shot examples)
-
خلاصهسازی مکالمات قبلی
-
یادگیری از تعاملات گذشته
استفاده میشود. این حافظه به مدل کمک میکند از تجربههای قبلی الهام بگیرد، نه فقط از دانش خام.
3)حافظه رویهای (Procedural Memory): نحوهی رفتار سیستم
حافظهی رویهای مشخص میکند که سیستم چگونه باید رفتار کند، نه اینکه چه چیزی را بداند. این حافظه شامل مواردی مثل:
-
شخصیت کلی سیستم
-
الگوهای پاسخگویی
-
قوانین و دستورالعملهای رفتاری
در مدلهای زبانی، این نوع حافظه معمولاً از طریق:
-
system prompt
-
قوانین ثابت
-
یا دستورالعملهایی که بهمرور و با بازخورد اصلاح میشوند
پیادهسازی میشود.
میتوان گفت حافظهی رویهای همان چیزی است که باعث میشود یک مدل «چگونه پاسخ بدهد»، حتی اگر محتوای پاسخ تغییر کند.
تفکیک حافظه به انواع مختلف نشان میدهد که «حافظه در مدلهای زبانی» یک مفهوم واحد و ساده نیست. بسته به کاربرد، ممکن است به:
-
دانش پایدار
-
تجربههای گذشته
-
یا الگوهای رفتاری
نیاز داشته باشیم.
همین نگاه چندلایه به حافظه است که پایهی سیستمهای پیشرفتهتر مبتنی بر LLM را میسازد و مسیر توسعهی آنها را شکل میدهد.
حتماً 👍
این بخش رو بهصورت آمادهی اضافهکردن به بلاگ مینویسم؛
لحنش همراستا با بقیهی متن: ساده، علمی، منسجم، نه خیلی فنی.
میتونی اینو بعد از بخش «انواع حافظه» یا قبل از جمعبندی نهایی بذاری.
حافظهها چه زمانی ساخته میشوند؟ (Active و Background Memory)
تا اینجا دربارهی «انواع حافظه» در سیستمهای مبتنی بر مدلهای زبانی صحبت کردیم، اما یک سؤال مهم دیگر باقی میماند:
این حافظهها دقیقاً چه زمانی ساخته یا بهروزرسانی میشوند؟
در عمل، حافظهها میتوانند به دو روش اصلی شکل بگیرند که هرکدام برای نیاز متفاوتی مناسب هستند: حافظهسازی فعال و حافظهسازی در پسزمینه.
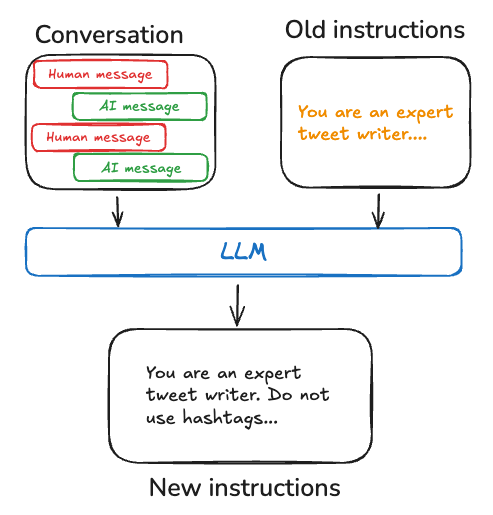
1)حافظهسازی فعال (Active / Hot Path)
در حافظهسازی فعال، استخراج و ثبت حافظه همزمان با جریان گفتگو انجام میشود. یعنی وقتی کاربر در حال تعامل با سیستم است، مدل یا عامل تلاش میکند اطلاعات مهم را تشخیص دهد و همان لحظه آنها را به حافظهی بلندمدت اضافه یا بهروزرسانی کند.
این رویکرد برای اطلاعاتی مناسب است که:
- اهمیت فوری دارند
- باید بلافاصله در پاسخهای بعدی لحاظ شوند
- از دست رفتن آنها تجربهی کاربر را خراب میکند
مثلاً ترجیح نام کاربر یا تغییر ناگهانی هدف گفتگو.
البته این روش یک هزینه هم دارد: چون پردازش حافظه در مسیر اصلی پاسخ انجام میشود، ممکن است کمی تأخیر در پاسخگویی ایجاد کند.
2)حافظهسازی در پسزمینه (Background / Subconscious)
در مقابل، حافظهسازی در پسزمینه بعد از پایان گفتگو (یا در زمانهای غیرفعال) انجام میشود. در این حالت، سیستم بدون فشار زمانی:
- مکالمات قبلی را مرور میکند
- الگوها و نکات مهم را استخراج میکند
- حافظهها را بهصورت دقیقتر و پایدارتر بهروزرسانی میکند
این روش برای مواردی مثل:
- استخراج شخصیت یا علایق کلی کاربر
- خلاصهسازی تعاملات گذشته
- یادگیری از تجربههای موفق
بسیار مناسب است.
مزیت اصلی این رویکرد این است که هیچ تأخیری در پاسخهای آنی ایجاد نمیکند و به سیستم اجازه میدهد با دقت بیشتری از تجربهها یاد بگیرد.
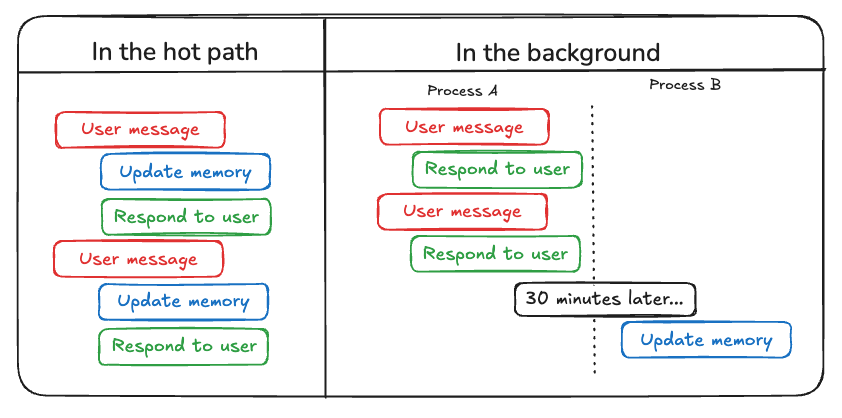
ترکیب این دو رویکرد
در سیستمهای پیشرفته، این دو روش معمولاً در کنار هم استفاده میشوند.
حافظهسازی فعال کمک میکند سیستم در لحظه واکنش مناسبی نشان دهد، و حافظهسازی در پسزمینه باعث میشود در بلندمدت هوشمندتر و سازگارتر شود.
به همین دلیل، زمانبندی ساخت حافظه به اندازهی نوع حافظه اهمیت دارد و نقش مهمی در کیفیت نهایی تعامل با مدلهای زبانی ایفا میکند.
جمعبندی: حافظه، یکی از چالشهای کلیدی مدلهای زبانی
حافظه در مدلهای زبانی مفهومی ساده به نظر میرسد، اما در عمل یکی از پیچیدهترین و مهمترین چالشهای آنهاست. آنچه ما بهعنوان «به خاطر سپردن» در تعامل با این مدلها تجربه میکنیم، در واقع استفادهی موقت از اطلاعات موجود در بافت گفتگو است، نه حافظهای پایدار شبیه به حافظهی انسان.
در طول این مطلب دیدیم که حافظه چگونه به مدلهای زبانی کمک میکند تا مکالمهای منسجم داشته باشند، پاسخهای مرتبطتری ارائه دهند و در سیستمهای واقعی مثل چتباتها و دستیارهای هوشمند کاربردیتر شوند. در عین حال، محدودیتهایی مانند پنجرهی متن محدود و فراموشی اطلاعات قدیمی نشان میدهند که حافظهی فعلی LLMها هنوز فاصلهی زیادی با انتظارات انسانی دارد.
به همین دلیل، حافظه یکی از محورهای اصلی پژوهش و توسعه در مدلهای زبانی محسوب میشود. راهکارهایی برای بهبود این وضعیت وجود دارد؛ از طراحیهای هوشمندانهتر برای مدیریت context گرفته تا استفاده از سیستمهای حافظهی خارجی. پرداختن به این راهکارها میتواند گام مهمی در ساخت مدلهایی باشد که تعامل با آنها طبیعیتر، دقیقتر و پایدارتر است.