هوش مصنوعی
پایگاه دانش RAG چیست؟ راهنمای اتصال دیتای اختصاصی به هوش مصنوعی
بیایید یک سناریوی ملموس را تصور کنیم: فرض کنید آلبرت اینشتین را به عنوان مدیر پشتیبانی شرکتتان استخدام کردهاید. او نابغه است، قدرت تحلیل بینظیری
 امیر محسن
امیر محسن
بیایید یک سناریوی ملموس را تصور کنیم: فرض کنید آلبرت اینشتین را به عنوان مدیر پشتیبانی شرکتتان استخدام کردهاید. او نابغه است، قدرت تحلیل بینظیری
امیر محسنبیایید یک سناریوی ملموس را تصور کنیم: فرض کنید آلبرت اینشتین را به عنوان مدیر پشتیبانی شرکتتان استخدام کردهاید. او نابغه است، قدرت تحلیل بینظیری دارد و پیچیدهترین مسائل را حل میکند. اما در روز اول کاری، وقتی مشتری تماس میگیرد و میپرسد: «شرایط بازگشت کالا در جشنواره تابستانه امسال چیست؟»، اینشتین سکوت میکند.
چرا؟ آیا دانش او کافی نیست؟ ابداً! مشکل اینجاست که اینشتین هرچقدر هم نابغه باشد، اسناد داخلی شرکت شما را مطالعه نکرده است. او «دانش عمومی جهان» را دارد، اما از «دانش خصوصی و لحظهای سازمان» شما بیخبر است. مدلهای زبانی بزرگ (LLMs) دقیقاً در همین وضعیت هستند. آنها اینشتینهایی هستند که دانششان در زمان آموزش منجمد شده است. آنها نه قیمت لحظهای ارز را میدانند، نه ایمیلهای دیروز مدیرعامل را خواندهاند و نه دسترسی به دیتابیس SQL شما دارند.
راه حل چیست؟ باید سیستمی ایجاد کنیم که اسناد مورد نیاز را در لحظه جستجو کرده و در اختیار مدل قرار دهد. به این معماری، RAG (Retrieval-Augmented Generation) یا «تولید متن با کمک بازیابی» میگویند و آن مخزن اسناد حیاتی، همان پایگاه دانش است. در این مقاله، معماری این معماری را بررسی میکنیم تا هوش مصنوعی ما دیگر در پاسخ به سوالات تخصصی ناتوان نماند.
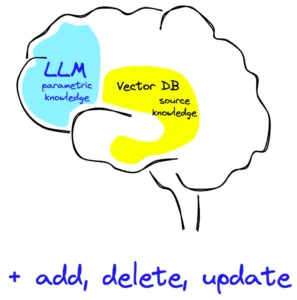
برای درک عمیق پایگاه دانش و چرایی نیاز به RAG، ابتدا باید بدانیم که «دانش» در مدلهای زبانی چگونه ذخیره و بازیابی میشود. درست مانند مغز انسان که دو نوع کارکرد حافظه دارد، هوش مصنوعی نیز از دو منبع متفاوت برای پاسخگویی استفاده میکند:
حافظه پارامتریک همان دانش فشرده و انتزاعی است که در قلب مدل و در میان میلیاردها پارامتر (Weights) آن ذخیره شده است. وقتی مدلهایی مثل GPT یا Llama آموزش میبینند، تمام کتابها و مقالاتی را که خواندهاند، حفظ نمیکنند؛ بلکه الگوها، روابط و ساختارها را یاد میگیرند.
این همان حافظهای است که RAG را ممکن میسازد. در اینجا، دانش در داخل مدل ذخیره نمیشود، بلکه در منابعی خارج از مدل مانند) وکتور دیتابیسها، فایلهای PDF یا ویکیپدیا(نگهداری میشود و مدل صرفاً به آنها دسترسی دارد.
معماری RAG دقیقاً پل ارتباطی بین این دو نوع حافظه است.
در واقع، RAG به مدل اجازه میدهد تا برای استدلال از مغز خودش استفاده کند، اما برای بیان حقایق، به کتابچه راهنمای شما نگاه کند.
پایگاه دانش (Knowledge Base) در سیستمهای RAG، صرفاً یک محل ذخیرهسازی نیست؛ بلکه هستهی مرکزی چرخه «بازیابی ← بازنمایی ← تولید پاسخ» است. بسته به اینکه «جنس» دادههای اختصاصی شما چیست و کاربران به دنبال چه نوع پاسخهایی هستند، سه معماری استاندارد برای مهندسی این بخش وجود دارد:
این معماری رایجترین و شاید حیاتیترین بخش محسوب میشود، چرا که حجم عظیمی از دانش داخلی و تخصصی در قالب دادههای بدون ساختار و متنی نهفته است. از فایلهای PDF و قراردادها گرفته تا ایمیلها، چتهای کاری/تیمی و مقالات وبلاگ، همگی در این دسته قرار میگیرند.
مکانیزم عملکرد: در این معماری، ما یک خط لوله (Pipeline) مشخص داریم: ابتدا متون خام توسط استراتژیهای Chunking قطعهبندی میشوند.
این معماری مخصوص دادههایی است که نظم ذاتی دارند و در قالب جداول، ستونها و رکوردهای دقیق تعریف شدهاند. منابعی مانند فایلهای Excel، CSV و دیتابیسهای رابطهای (SQL) که حاوی دادههای مالی، تراکنشی و عملیاتی هستند، خوراک این سیستماند.
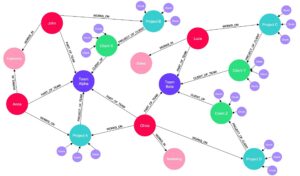
این پیشرفتهترین و بالغترین نوع معماری در سیستمهای RAG است. در گراف دانش، ما به جای ذخیره صرف اطلاعات، روابط بین آنها را ذخیره میکنیم. این ساختار از سهتاییهای «موجودیت ← رابطه ← موجودیت» تشکیل شده است (مانند: علی رضایی ← مدیریت میکند ← پروژه X.)
ساخت این پایگاه دانش نیازمند فرآیند دقیق استخراج موجودیت و رابطه است. دادهها در دیتابیسهای گرافی قدرتمند مثل Neo4j یا Amazon Neptune ذخیره میشوند. در زمان پرسش، مدل میتواند با پیمایش گراف، ارتباطات پنهان بین دادهها را کشف کند.
ساخت یک پایگاه دانش کارآمد، فراتر از کپی کردن فایلهاست. این یک فرآیند مهندسی دقیق است که به آن ETL for AI میگویند. بیایید مراحل حیاتی این خط لوله را بررسی کنیم:
اولین قدم، جمعآوری دادهها از منابع مختلف (PDF, Docx, Web, SQL) است.
شما نمیتوانید یک کتاب ۱۰۰ صفحهای را یکجا به مدل بدهید (به دلیل محدودیت Context Window). باید متن را به قطعات کوچکتر خرد کنید. اما چگونه؟
نقش حیاتی متادیتا: فرض کنید کاربر میپرسد: «گزارش فروش ماه گذشته چطور بود؟»
{
"text": "فروش ما ۲۰٪ رشد داشت...",
"metadata": {
1404:"سال",
"مرداد": "ماه",
"مدیر فروش": "نویسنده",
"مدیران ": "سطح_دسترسی"
}
}
اکنون میتوانید قبل از جستجو فیلتر کنید: «فقط در اسناد ۱۴۰۴ جستجو کن». این کار دقت را به طرز چشمگیری افزایش میدهد.
دیتابیسهای رابطهای سنتی (SQL) برای جستجوی معنایی مناسب نیستند. ما به ابزارهایی تخصصی مثل Pinecone, Milvus یا Qdrant نیاز داریم که از الگوریتمهایی مانند HNSW برای جستجوی فوقسریع در میان میلیونها بردار استفاده میکنند.
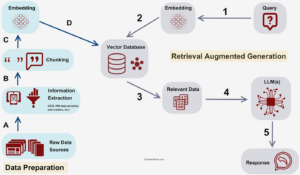
پس از آمادهسازی پایگاه دانش، وقتی سوالی پرسیده میشود، چه اتفاقی میافتد؟
سیستم به دنبال مفهوم میگردد، نه صرفاً کلمات کلیدی.
گاهی اوقات جستجوی وکتور در مواجهه با کلمات خاص دچار خطا میشود.
گراف دانش (GraphRAG): این جدیدترین رویکرد در سیستمهای RAG است. وکتور دیتابیسها در درک “روابط پیچیده” ضعف دارند.
ساخت سیستم آسان است، اما اطمینان از کیفیت خروجی چالشبرانگیز است. ما با استفاده از فریمورکهایی مثل RAGAS سه شاخص کلیدی را میسنجیم:
تمام چیزی که تا اینجا گفتیم از ساخت پایگاه دانش، چانکینگ و پاکسازی دادهها، تا بردارسازی، مدیریت متادیتا، جستجوی معنایی، Hybrid Search و حتی ارزیابی RAG در ظاهر یک معماری پیچیده و کاملاً فنی است.
اما نکته مهم اینجاست:
شما بدون حتی یک خط کدنویسی میتوانید تمام این فرایندها را در هوشیار انجام دهید.
در هوشیار نیازی نیست درگیر Vector Database، مدلهای Embedding، طراحی چانکینگ یا پیادهسازی Retrieval شوید.
فقط کافیست اسناد خود را بارگذاری کنید؛ هوشیار همه مراحل مهندسی داده، ایندکسگذاری و بازیابی را بهصورت خودکار انجام میدهد و یک پایگاه دانش حرفهای و آمادهبرای-RAG را برایتان میسازد.
اگر به دنبال ساخت یک سیستم هوش مصنوعی کاربردی، دقیق و سازمانی هستید، هوشیار مسیر را برایتان هموار کرده است.